
[Computer Organization & Design] Instructions: Language of the Computer - Part 2
https://kangcoder.tistory.com/entry/Computer-Organization-Design-Instructions-Language-of-the-Computer-Part-1 [Computer Organization & Design] Instructions: Language of the Computer - Part 1 Instruction Set 컴퓨터에서 사용되는 명령어들의 집
kangcoder.tistory.com
Six Steps in Procedure Calling
함수가 호출되었을 때, 실행되는 6단계
1. 메인 routine(Caller)이 parameter를 프로시저(Callee)가 접근 가능한 곳에 위치시킨다.
2. Caller가 제어권을 Callee에게 넘겨준다.
3. Callee는 필요한 메모리를 얻는다.
4. Callee가 작업(Callee가 수행하기로 한 서브 루틴)을 수행한다.
5. Callee의 작업의 결과값을 Caller가 접근 가능한 곳에 위치시킨다.
6. 제어권을 다시 Caller에게 반납한다.
Instructions for Procedure Call
프로시저(Callee)를 call하기 위한 MIPS Instructions => jal (jump and link), jr (jump register)
jal ProcedureAddress (J-format)

- 이 바로 다음에 올 Inst.의 주소를 $ra에 담는다. (프로시저가 종료되면 바로 다음 Inst.를 수행하기 위해)
- ProcedureAddress(프로시저가 수행되기 위해 Label된 주소)로 점프한다.
- return value를 $ra에 link한다.
jr $ra (R-format)

- PC에 $ra값을 복사한다. (프로시저 다음 Inst.로 돌아와 계속 수행하기 위함)
Leaf Procedure
- 프로시저(함수) 내에서 다른 프로시저를 호출하지 않는다.


Non-Leaf Procedure
- 프로시저(함수) 내에서 다른 프로시저를 호출하는 형태. (call하고 안에서 또 call하고 ..)
- 내포된 호출이 있으므로 Caller는 스택에 다음 값들을 저장해야 한다.
- 반환될 주소
- 필요한 매개값이나 임시값
- call 이후에 스택에 저장해둔 값을 복구시켜야 한다.
Local Data on the Stack
프로그램에서 프로시저(함수)가 호출되면 메모리가 어떻게 할당될까?
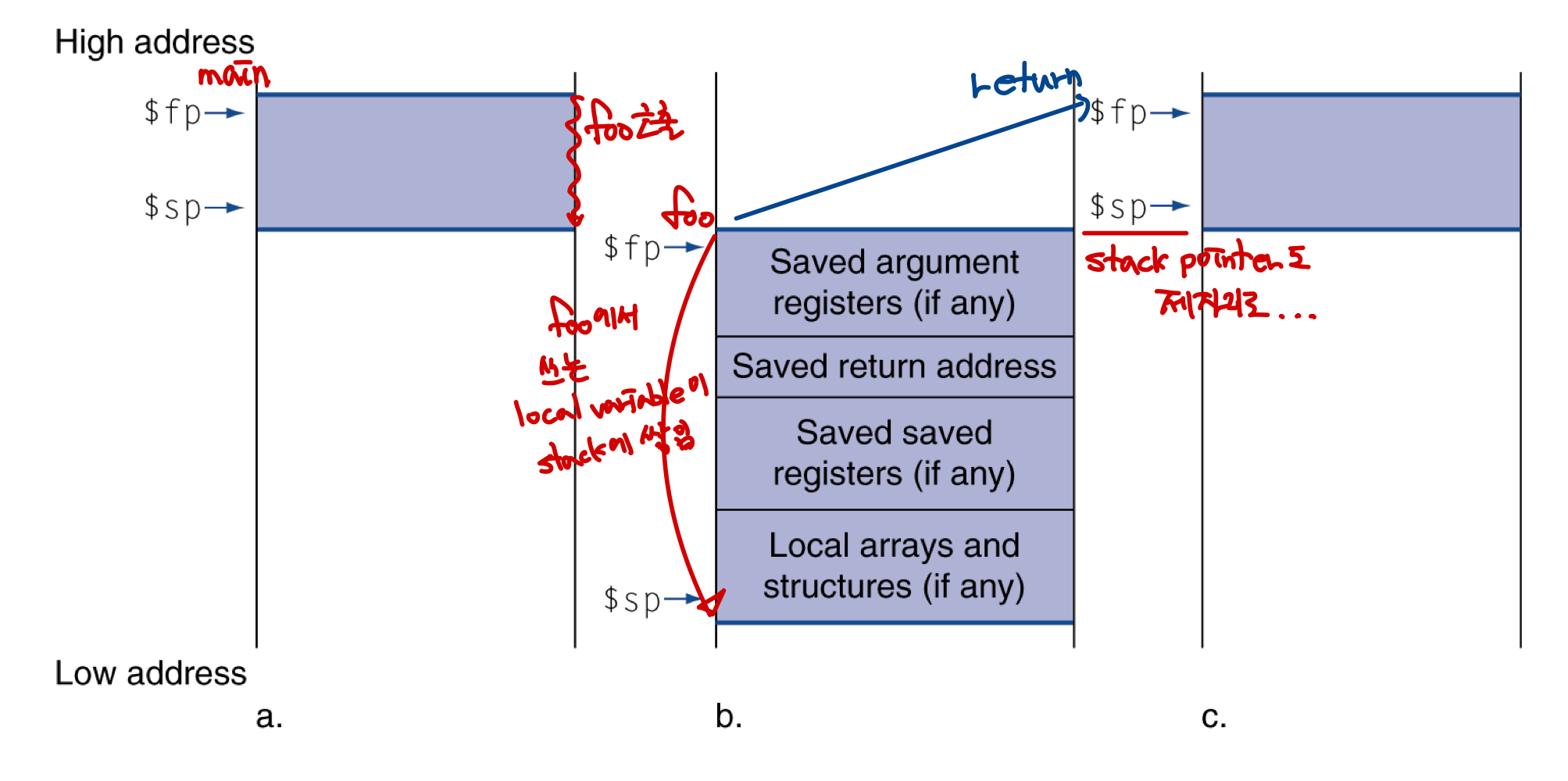
- $sp는 스택의 top을 가리키고 있고, $fp는 이번 프로시저에 할당되기 직전 가리키고 있던 stack pointer를 가리키고 있다.
- foo라는 프로시저가 호출되면 현재 main의 실행 상태를 보존하기 위해 foo의 호출에 필요한 인자, return address 등이 스택에 저장된다.
- sp는 호출된 foo의 sp를 가리키기 위해 감소하고, 이전 sp의 위치를 추적하기 위해 fp가 main의 sp를 가리키도록 업데이트 된다.
- 프로시저 프레임(actication record)
- 하나의 프로시저(함수)가 실행될 때 할당되는 메모리 공간 ($fp에서 $sp까지)
Synchronization
2개 이상의 프로세서(또는 쓰레드)가 특정 주소공간(메모리)에 동시에 접근
- 데이터의 접근 순서를 잘 조절해야 한다.
- 하드웨어적으로 지원해야 사용가능하다.
Assembler Pseudoinstructions
유사 Instruction (대체 명령어)
- 실제 MIPS Instructions에는 없지만, 어셈블러에서 사용할 수 있는 가짜 명령어
- 어셈블러가 이 명령어들을 실제 MIPS Instruction으로 바꿔준다.
move $t0, $t1 -> add $t0, $zero, $t1
blt $t0, $t1, L -> slt $at, $t0, $t1
bne $at, $zero, L
Translation and Startup
예시로 C program이 실행되는 과정을 살펴보자.

1. C언어로 작성된 프로그램(*.c)을 컴파일러가 어셈블리어 프로그램(*.a)으로 번역
2. 어셈블리어 프로그램(*.a)을 어셈블러가 오브젝트(*.o, *.obj)로 변환
3. 작성한 코드로 만들어진 오브젝트와 라이브러리에 의해 만들어진 여러 오브젝트들을 링커가 묶어 실행가능한 기계어 프로그램(*.exe)로 작성 -> 이 과정을 static linking이라고 한다.
4. 만들어진 실행파일을 실행하려면? -> 실행파일을 로더가 메모리에 올린다.
Fallacies
1. 복잡한(강한) Instruction이 무조건 고성능일 것이다?
- 하나의 instruction을 복잡하게 만들면 전체적인 instruction이 줄어드니 더 성능이 좋아질 것이라는 착각이 있다.
- 하지만 복잡한 instruction은 오히려 더 성능을 나빠지게 한다. (해당 instruction을 실행하기 위해 더 느린 clock을 사용해야 하니..)
- 따라서 전체적으로 더 성능이 느려질 수도 있다.
2. assembly code로 개발하면 더 성능이 좋을 것이다?
- 현대의 컴파일러들은 최적화를 잘해주기 때문에, 충분히 high-level language로도 어셈블리 코드와 유사한 성능을 낼 수 있다.
- 오히려 어셈블리 코드로 작성할 경우 개발자의 실수를 더 유발할 수 있고, 개발 생산성도 떨어트릴 수 있다.
(임베디드 시스템과 같은 특수한 경우는 어셈블리 코드를 작성해야 할 때도 있음..)
3. 하위 호환성을 유지하기 위해 Instruction Set을 바꾸지 않을 것이다?
- 그렇지 않다. 기존의 것은 계속 지원하되 새로운 Instruction Set도 계속해서 추가하고 있다.
Pitfalls
1. 순차적인 word는 순차적인 address에 놓여있지 않다.
- word는 4byte이므로 당연히 4씩 증가하지, 1씩 순차적으로 증가하지 않는다.
2. 프로시저(함수)가 끝나면 해당 프로시저 내부의 local variable을 가리키는 pointer를 사용하면 안된다.
- 프로시저가 종료되면 해당 local variable은 스택에서 pop되기 때문에 가리켜봤자 값이 없다.